![[Python] 한글 내용이 같지만 다르다고 인식하는 경우](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbsHFG6%2FbtqYmIhHtHC%2FAAAAAAAAAAAAAAAAAAAAAEUbE_z3UFXkfJZq7i6mI-cPjPculLMB3ranF9-bXHpR%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DnaBx%252FGPPHkUH0T5FMksstcAmCLg%253D)
분석 환경
Google Colab pro의 구성환경
- Python Version : 3.7.10
상황
눈으로 볼 땐 두 한글 변수의 값이 같지만 비교 연산자 실행 시 다르다고 인식하는 상황.
더 나아가 두 변수를 같게끔 인식 시키고 싶은 상황.
>>> # 두 변수 확인
>>> print('str1 : ' + temp_str1)
>>> print('str2 : ' + temp_str2)
>>> # 두 변수가 같은지 확인
>>> temp_str1 == temp_str2str1 : 전국보행자전용도로표준데이터
str2 : 전국보행자전용도로표준데이터
False분명 눈으로는 두 변수가 정확히 일치하는 것처럼 보이지만 두 변수가 같지 않다고 인식한다.
왜 그런지에 대해 알아보고자 많은 시행착오를 거쳤다.
시행착오
알게 된 점
1. 'UTF-8'로 출력해보면 내용이 다르다.
temp_str1
>>> print(temp_str1.encode('utf-8'))b'\xec\xa0\x84\xea\xb5\xad\xeb\xb3\xb4\xed\x96\x89\xec\x9e\x90\xec\xa0\x84\xec\x9a\xa9\xeb\x8f\x84\xeb\xa1\x9c\xed\x91\x9c\xec\xa4\x80\xeb\x8d\xb0\xec\x9d\xb4\xed\x84\xb0'
temp_str2
>>> print(temp_str2.encode('utf-8'))b'\xe1\x84\x8c\xe1\x85\xa5\xe1\x86\xab\xe1\x84\x80\xe1\x85\xae\xe1\x86\xa8\xe1\x84\x87\xe1\x85\xa9\xe1\x84\x92\xe1\x85\xa2\xe1\x86\xbc\xe1\x84\x8c\xe1\x85\xa1\xe1\x84\x8c\xe1\x85\xa5\xe1\x86\xab\xe1\x84\x8b\xe1\x85\xad\xe1\x86\xbc\xe1\x84\x83\xe1\x85\xa9\xe1\x84\x85\xe1\x85\xa9\xe1\x84\x91\xe1\x85\xad\xe1\x84\x8c\xe1\x85\xae\xe1\x86\xab\xe1\x84\x83\xe1\x85\xa6\xe1\x84\x8b\xe1\x85\xb5\xe1\x84\x90\xe1\x85\xa5'
이제 눈으로 두 변수가 서로 다른 내용을 저장하고 있다는 것을 확인했다. 인코딩을 달리하면 두 변수를 같게끔 만들어 주지 않을까 싶어 'euc-kr', 'cp949', 'utf-16' 등 안 해본 인코딩이 없을 정도로 시도해보았지만 허탕이었다.
2. 두 문자열의 길이가 다르다.
>>> print(temp_str1)
>>> print(temp_str2)전국보행자전용도로표준데이터
전국보행자전용도로표준데이터눈으로 보기에는 두 변수의 값이 같다. 혹시나 컴퓨터가 인식하는 문자열의 길이가 다를까 싶어 확인해보았다.
>>> print(len(temp_str1))
>>> print(len(temp_str2))14
34'전국보행자전용도로표준데이터'는 14글자로 이루어져 있다. 그래서 두 변수 모두 문자열의 길이를 14로 예상하면서 코드를 실행해보았다.
temp_str1변수는 문자열의 길이가 14로 출력이 되는 반면 temp_str2변수는 문자열의 길이가 34로 출력이 되는 것을 확인할 수 있었다.
temp_str2 변수는 왜 문자열의 길이가 34 인 것일까?
하나하나의 원소를 파헤쳐 보고 나서야 비로소 이유를 알 것 같았다.
>>> print(temp_str2[0])
>>> print(temp_str2[1])ㅈ
ㅓ확인해보니 temp_str2 변수는 자음 모음이 분리된 상태로 원소화 되어있었다.
이러한 정보를 가지고 많은 구글링을 통해 해결방법을 찾을 수 있었다.
한글이 자음 모음 형태로 분리되어 깨질 때 해결방안
unicodedata 모듈
- 이 모듈은 모든 유니코드 문자에 대한 문자 속성을 정의하는 유니코드 문자 데이터베이스에 대한 액세스를 제공한다.
이 상황(자음 모음이 분리되어 있는 경우)에서는 해당 모듈 내에 정의되어있는 normalize 함수를 사용하여 자음 모음을 합칠 수 있다. 또한 반대로 기존 한글 문장을 자음 모음으로 분리하는 것도 가능하다.
unicodedata.normalize(form, unistr)
form
-'NFD'- 자음 모음으로 분리
-'NFC'- 자음 모음을 결합unistr
- 적용할string변수를 매개변수로 지정
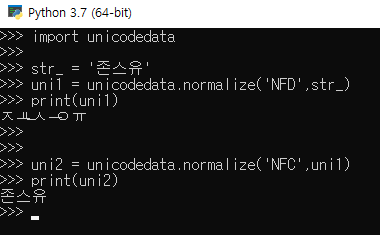
>>> import unicodedata
>>> # 경우 1 : 한글 문자열을 자음 모음으로 분리하기
>>> uni1 = unicodedata.normalize('NFD',temp_str1)
>>> # 경우 2 : 분리된 자음 모음을 결합하기
>>> uni2 = unicodedata.normalize('NFC',temp_str2)
>>> print(uni1) # 자음 모음으로 분리된 형태
>>> print(uni2) # 자음 모음이 합쳐진 형태전국보행자전용도로표준데이터
전국보행자전용도로표준데이터여기서 혼란스러울 수 있겠지만 위의 코드 블럭의 내용은 모두 Colab Notebook에서 출력되는 모습을 나타낸 것이다. Colab Notebook에서 출력되는 모습은 위의 사진 속 prompt에서 처럼 출력이 되는 것이 아니라, 자음 모음이 분리된 형태이든 아니든 간에 모두 자음 모음이 합쳐진 형태로 출력된 모습이다. (결국 이것이 혼란스러움의 원인이라는 말)
그렇기 때문에 Colab Notebook 환경에서는 저 출력된 모습만 보고선 판단하면 안된다. 제대로 자음 모음으로 분리가 되었는지, 혹은 자음 모음이 합쳐져 정상적인 한글 문자열이 되었는지 간단히 확인하기 위해서는 문자열의 길이 비교가 하나의 방법이 될 수 있다.
- NFD
한글 문자열을 자음 모음으로 분할
Colab Notebook 에서 출력되기 때문에 눈으로는 변화가 힘들지만 변수 내 원소 하나를 비교해 보았을 때 기존의 한글 문자열이 자음 모음으로 잘 분리된 것을 확인할 수 있다.
>>> # temp_str1
>>> print(f'Colab Notebook 출력 :{temp_str1}')
>>> print(f'첫번째 원소 : {temp_str1[0]}')
>>> print(f'문자열 길이 : {len(temp_str1)}')
>>> print()
>>> # temp_str1 -> uni1 (NFD) : 자음 모음으로 분할
>>> print(f'Colab Notebook 출력 :{uni1}')
>>> print(f'첫번째 원소 : {uni1[0]}')
>>> print(f'문자열 길이 : {len(uni1)}')Colab Notebook 출력 :전국보행자전용도로표준데이터
첫번째 원소 : 전
문자열 길이 : 14
Colab Notebook 출력 :전국보행자전용도로표준데이터
첫번째 원소 : ᄌ
문자열 길이 : 34
- NFC
하나하나의 자음 모음을 한글 문자열로 결합
Colab Notebook 에서 출력되기 때문에 눈으로는 변화가 힘들지만 변수 내 원소 하나를 비교해 보았을 때 자음 모음이 잘 합쳐진 것을 확인할 수 있다.
>>> # temp_str2
>>> print(f'Colab Notebook 출력 :{temp_str2}')
>>> print(f'첫번째 원소 : {temp_str2[0]}')
>>> print(f'문자열 길이 : {len(temp_str2)}')
>>> print()
>>> # temp_str2 -> uni2 (NFC) : 자음 모음을 결합
>>> print(f'Colab Notebook 출력 :{uni2}')
>>> print(f'첫번째 원소 : {uni2[0]}')
>>> print(f'문자열 길이 : {len(uni2)}')Colab Notebook 출력 :전국보행자전용도로표준데이터
첫번째 원소 : ᄌ
문자열 길이 : 34
Colab Notebook 출력 :전국보행자전용도로표준데이터
첫번째 원소 : 전
문자열 길이 : 14
비교 연산자를 통한 변수 비교
기존의 temp_str1과 temp_str2는 서로 같지 않다고 인식되었다.
>>> # 두 변수 확인
>>> print('str1 : ' + temp_str1)
>>> print('str2 : ' + temp_str2)
>>> # 두 변수가 같은지 확인
>>> temp_str1 == temp_str2str1 : 전국보행자전용도로표준데이터
str2 : 전국보행자전용도로표준데이터
False
하지만 이제 두 변수를 정상적인 한글 문자열 형태, 혹은 자음 모음이 분리된 형태 둘 중 하나로 통일만 시켜준다면 같게 인식 할 수 있을 것이다. (즉, 사용자의 편의성에 따라 하나로 규칙을 통일시키면 된다.)
정상적인 한글 문자열로 통일
>>> print(temp_str1)
>>> print(len(temp_str1))
>>> print(uni2)
>>> print(len(uni2))
>>> temp_str1 == uni2전국보행자전용도로표준데이터
14
전국보행자전용도로표준데이터
14
True
한글 문자열이 자음 모음으로 분리된 형태로 통일
>>> print(temp_str2)
>>> print(len(temp_str2))
>>> print(uni1)
>>> print(len(uni1))
>>> temp_str2 == uni1전국보행자전용도로표준데이터
34
전국보행자전용도로표준데이터
34
True결론
간혹 두 한글 변수의 값이 아무리 봐도 같은데 다르다고 인식이 되는경우, 하나의 변수가 자음 모음이 구분된 형태인 경우 일 수도 있으니 확인해보자. 그 후 사용자의 편의에 따라 가공하여 잘 사용하자. 나의 시행착오가 많은 도움이 되었으면 좋겠다.
참조
https://docs.python.org/ko/3/library/unicodedata.html
https://enkoding.tistory.com/27